32 private links

"Chinese authorities are cracking down on negative media coverage and social media commentary about the coronavirus outbreak, threatening anyone who breaches their rules with up to seven years in jail." including in private chats, with rumour defined as broadly as describing daily life


To maintain its authority, the Communist Party of China must keep the public convinced that everything is going according to plan. That means carrying out systemic cover-ups of scandals and deficiencies that may reflect poorly upon the party’s leadership, instead of doing what is necessary to respond.
But perhaps the most tragic part of this story is that there is little reason to hope that next time will be different. The survival of the one-party state depends on secrecy, media suppression and constraints on civil liberties. So, even as Chinese President Xi Jinping demands that the government increase its capacity
to handle “major risks”, China will continue to undermine its own – and the world’s – safety, to bolster the Communist Party’s authority.
When China’s leaders finally declare victory against the current outbreak, they will undoubtedly credit the party’s leadership. But the truth is just the opposite: the party is again responsible for this calamity.
Ax and BoTorch leverage probabilistic models that make efficient use of data and are able to meaningfully quantify the costs and benefits of exploring new regions of problem space. In these cases, probabilistic models can offer significant benefits over standard deep learning methods such as neural networks, which often require large amounts of data to make accurate predictions and don’t provide good estimates of uncertainty.
what nature can achieve with 16 neurons
Intercepting a moving object requires prediction of its future location. This complex task has been solved by dragonflies, who intercept their prey in midair with a 95% success rate. In this study, we show that a group of 16 neurons, called target-selective descending neurons (TSDNs), code a population vector that reflects the direction of the target with high accuracy and reliability across 360°. The TSDN spatial (receptive field) and temporal (latency) properties matched the area of the retina where the prey is focused and the reaction time, respectively, during predatory flights. The directional tuning curves and morphological traits (3D tracings) for each TSDN type were consistent among animals, but spike rates were not. Our results emphasize that a successful neural circuit for target tracking and interception can be achieved with few neurons and that in dragonflies this information is relayed from the brain to the wing motor centers in population vector form.

that got real deep
"We can’t seem to take each other seriously, except when we take each other way too seriously. This “darkness and light” battle seems to have created a situation where you are either on one side or the other. There is no middle ground. There is no nuance. We don’t agree to disagree. We just disagree. Even as we descend into a culture of memes and in-jokes, there is still the harsh reality of being human.
If one of the most valuable companies in the U.S. is willing to poke fun at their foibles, maybe we can continue working our jobs at a flawed, imperfect company as well."

In Finland, the number of homeless people has fallen sharply. The reason: The country applies the “Housing First” concept. Those affected by homelessness receive a small apartment and counselling – without any preconditions. 4 out of 5 people affected thus make their way back into a stable life. And: All this is cheaper than accepting …

Or “Top Ten Diet Myths Debunked“. That would have fit almost as well. Ok, so in retrospect, I think I screwed up on the title. Many myths just happened to be connected to intermittent fasting (meal frequency, breakfast skipping, etc.). Well, live and learn. November 4th Addendum Section added at the end of the article. …
Intermittent fasting (IF) is a dietary protocol where energy restriction is induced by alternate periods of ad libitum feeding and fasting. The present study has sought to investigate the relationshi...

PubMed comprises more than 30 million citations for biomedical literature from MEDLINE, life science journals, and online books. Citations may include links to full-text content from PubMed Central and publisher web sites.


The city that had been founded to police the traffic of opium became the epicenter of Hong Kong’s narcotics trade.
On this tiny rectangle of ground, a single community created something that had only existed before in the avant garde imagination: the “organic megastructure.”
Perhaps Kowloon was also the first, true, physical monument to the internet. A city that offered a glimpse into the infinite horizons, structural possibilities—and inherent amorality—of the digital realm.
Adata also aims to impress with the XPG Sage's read and write IOPS, which allegedly come in at 1,000,000 and 800,000.
Microsoft and NIST agree special characters shouldn't be required, and to not force password resets/changes, with an 8 character minimum
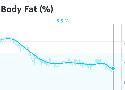
I’ve been following the NSNG (No Sugar No Grains) ‘way of eating’ for the last year and the results have been incredible. I weighed 191 pounds near the beginning of 2017 and today (Dec 7, 2017) I weighed in at 160. So, 31 pounds have disappeared, which is truly incredible. The statins I had been taking …
We show that this Neural Network-Gaussian Process correspondence surprisingly extends to all modern feedforward or recurrent neural networks composed of multilayer perceptron, RNNs (e.g. LSTMs, GRUs), (nD or graph) convolution, pooling, skip connection, attention, batch normalization, and/or layer normalization. More generally, we introduce a language for expressing neural network computations, and our result encompasses all such expressible neural networks. This work serves as a tutorial on the tensor programs technique formulated in Yang (2019) and elucidates the Gaussian Process results obtained there. We provide open-source implementations of the Gaussian Process kernels of simple RNN, GRU, transformer, and batchnorm+ReLU network at this http URL.
Wide neural networks with random weights and biases are Gaussian processes,
as originally observed by Neal (1995) and more recently by Lee et al. (2018)
and Matthews et al. (2018) for deep fully-connected networks, as well as by
Novak et al. (2019) and Garriga-Alonso et al. (2019) for deep convolutional
networks. We show that this Neural Network-Gaussian Process correspondence
surprisingly extends to all modern feedforward or recurrent neural networks
composed of multilayer perceptron, RNNs (e.g. LSTMs, GRUs), (nD or graph)
convolution, pooling, skip connection, attention, batch normalization, and/or
layer normalization. More generally, we introduce a language for expressing
neural network computations, and our result encompasses all such expressible
neural networks. This work serves as a tutorial on the tensor programs
technique formulated in Yang (2019) and elucidates the Gaussian Process results
obtained there. We provide open-source implementations of the Gaussian Process
kernels of simple RNN, GRU, transformer, and batchnorm+ReLU network at
github.com/thegregyang/GP4A.
pick the right raid chunk size
Planning problems are among the most important and well-studied problems in
artificial intelligence. They are most typically solved by tree search
algorithms that simulate ahead into the future, evaluate future states, and
back-up those evaluations to the root of a search tree. Among these algorithms,
Monte-Carlo tree search (MCTS) is one of the most general, powerful and widely
used. A typical implementation of MCTS uses cleverly designed rules, optimized
to the particular characteristics of the domain. These rules control where the
simulation traverses, what to evaluate in the states that are reached, and how
to back-up those evaluations. In this paper we instead learn where, what and
how to search. Our architecture, which we call an MCTSnet, incorporates
simulation-based search inside a neural network, by expanding, evaluating and
backing-up a vector embedding. The parameters of the network are trained
end-to-end using gradient-based optimisation. When applied to small searches in
the well known planning problem Sokoban, the learned search algorithm
significantly outperformed MCTS baselines.
repressed memories aren't a thing
The idea that people "block out" traumatic memories has been proven wrong over and over. Why, then, do therapists continue to promote it?